 Daisy-TTS
Daisy-TTS
Simulating Wider Spectrum of Emotions via Prosody Embedding Decomposition
Simulating Wider Spectrum of Emotions via Prosody Embedding Decomposition
We introduce Daisy-TTS, and emotional text-to-speech design, grounded on the structural model of emotions
Through learning and decomposing the learned embeddings, Daisy-TTS capable of simulating:
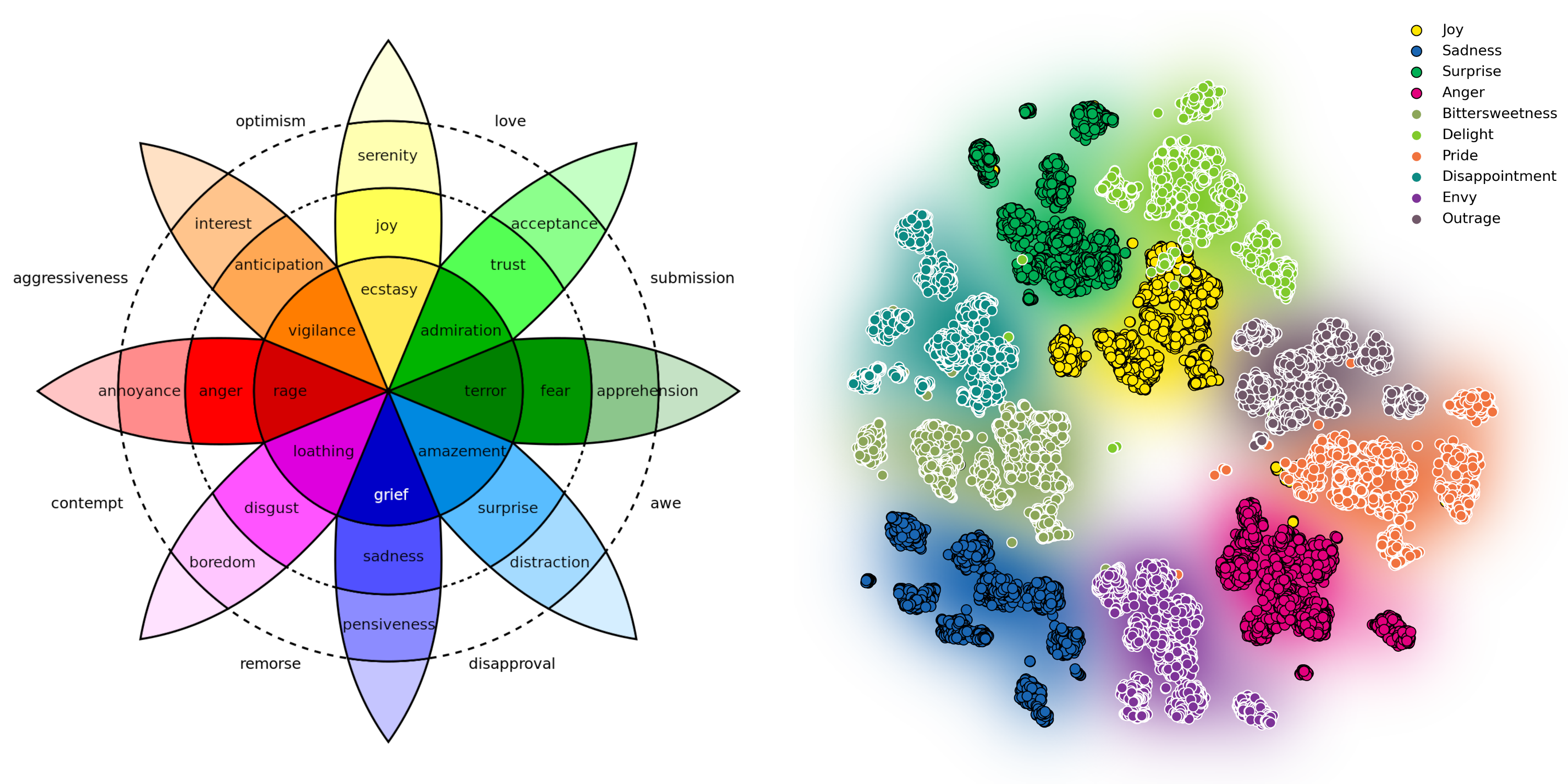
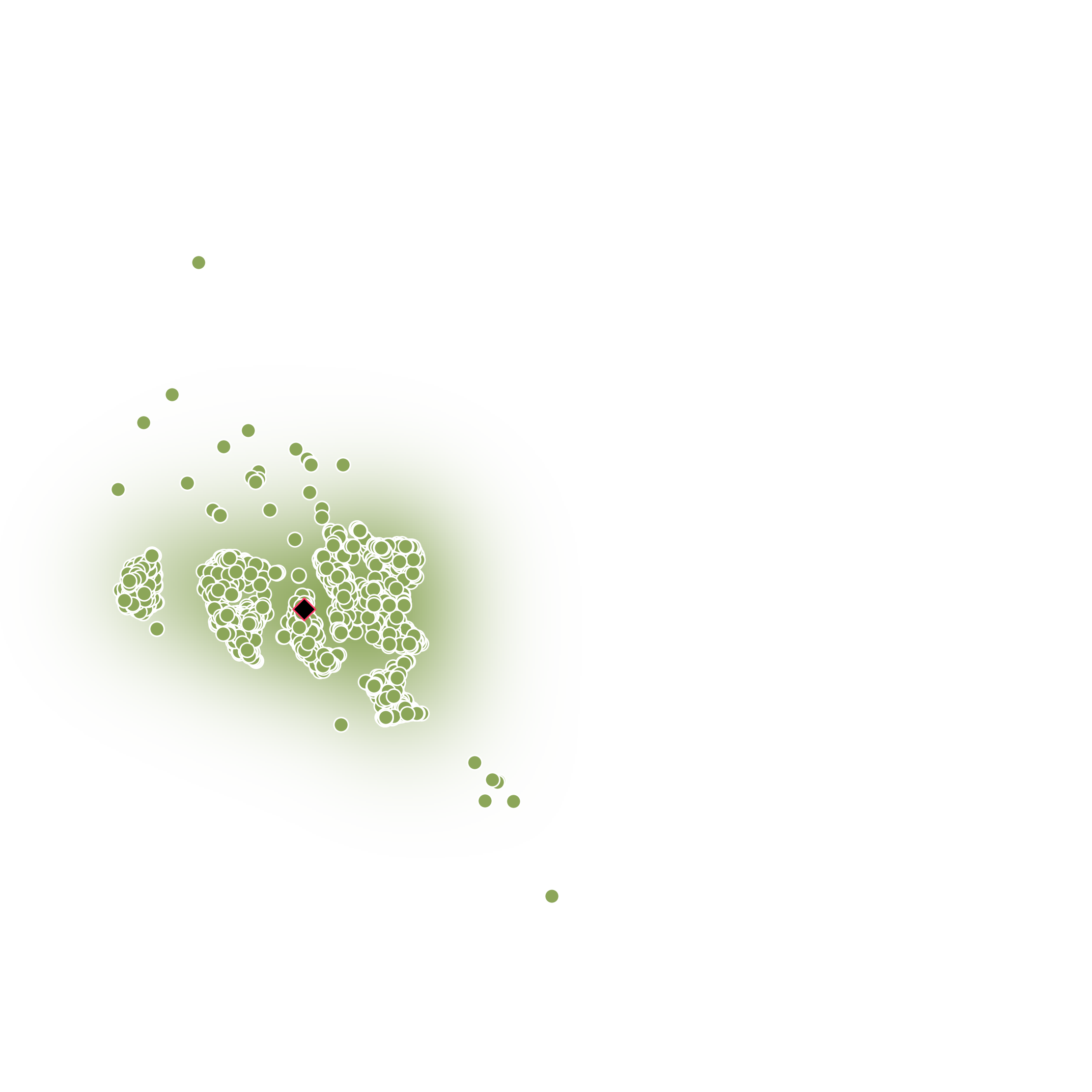
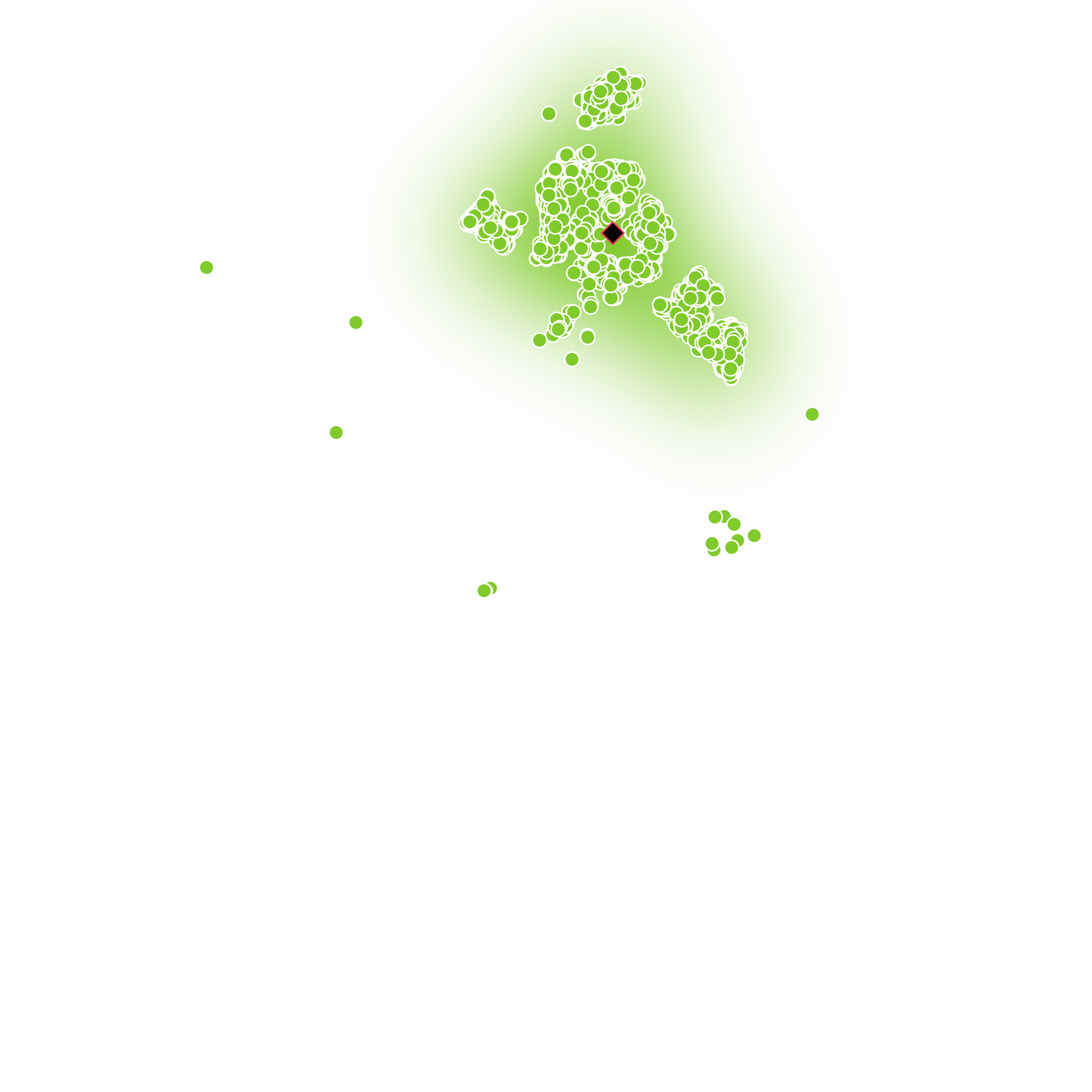
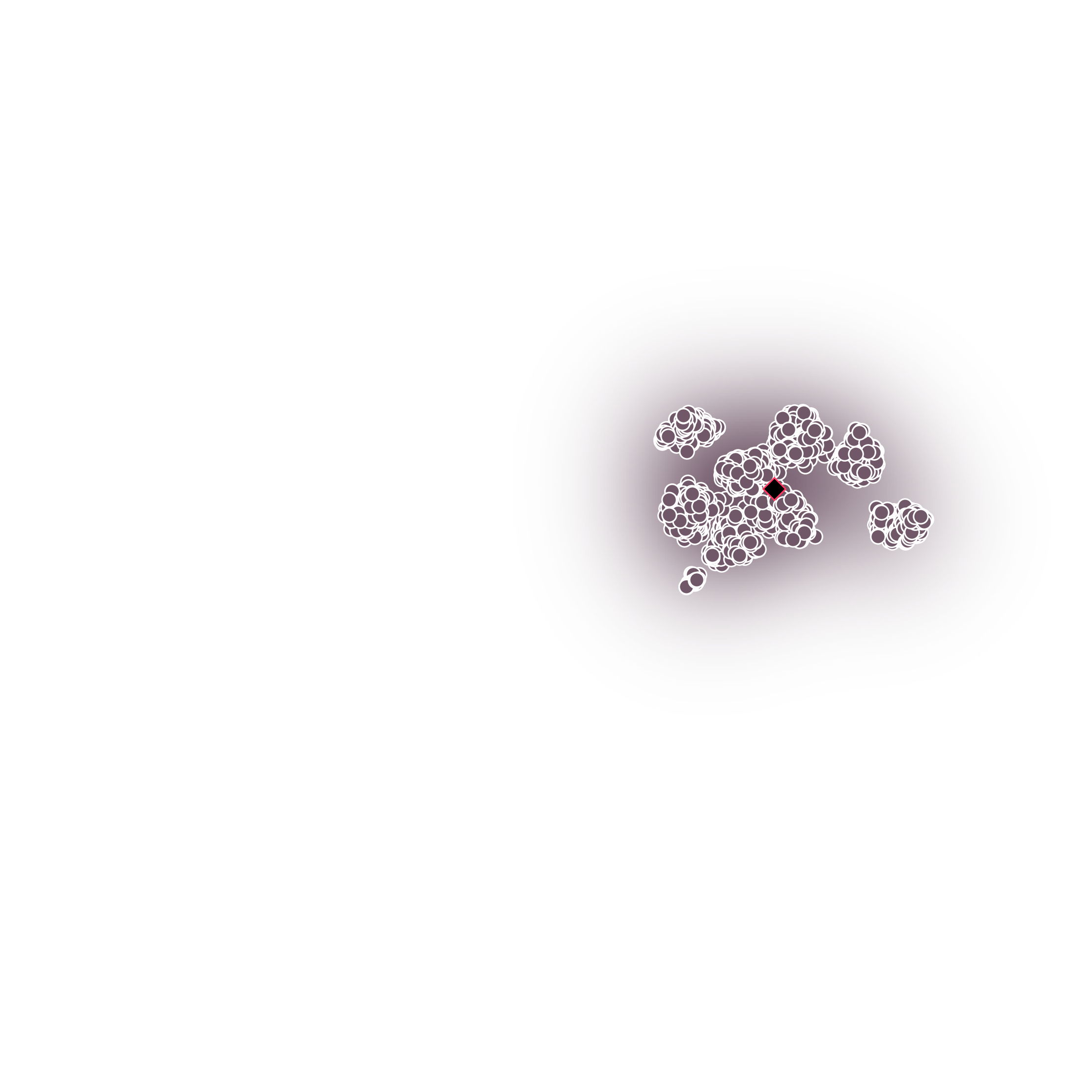
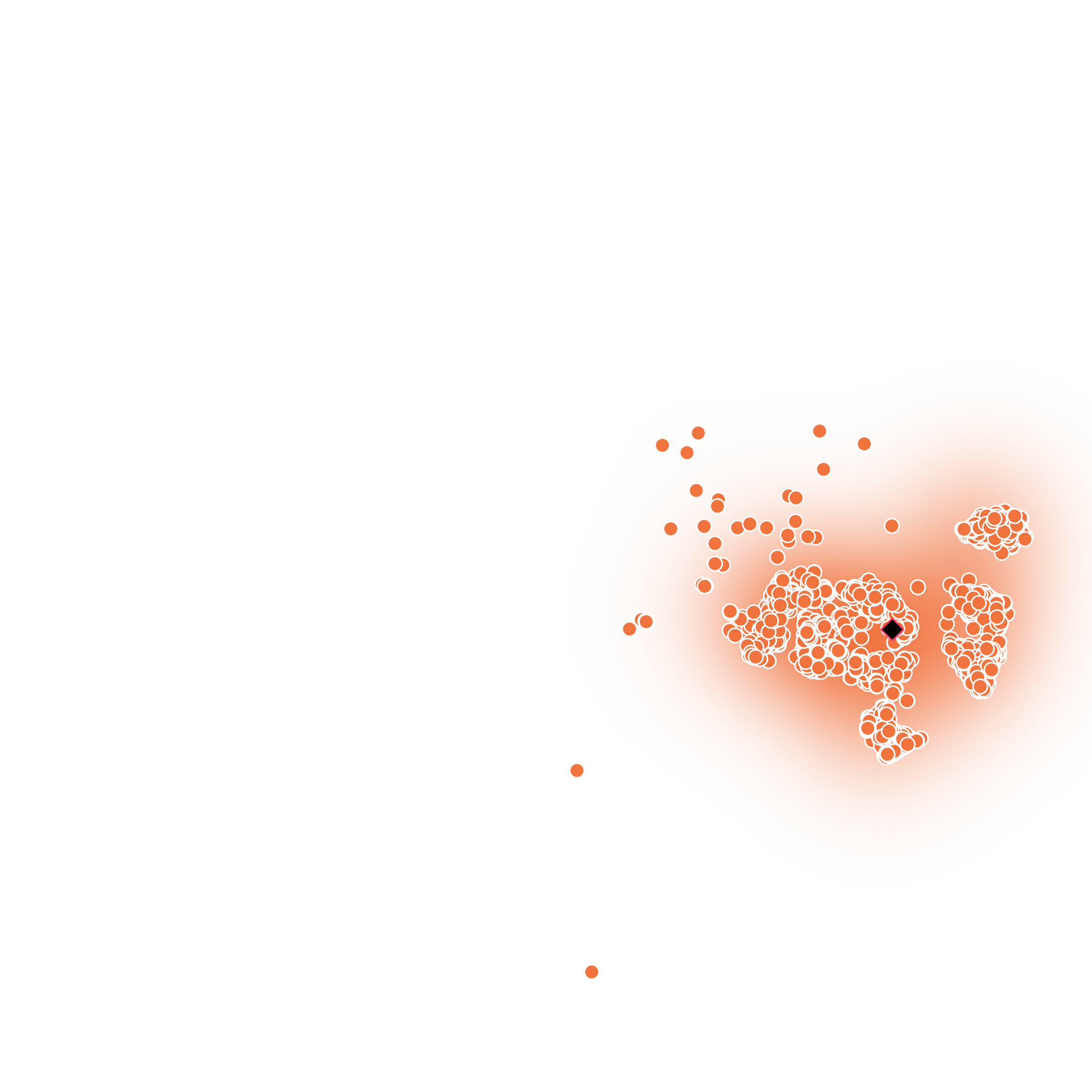
(Left) Structural Model of Emotions. (Right) Emotionally-separable prosody embeddings learned by Daisy-TTS.
Below we can listen to emotional speech simulated by Daisy-TTS, with algorithm described in Section 3 of the paper. We can simulate a primary emotion, or secondary emotion by mixing the primary ones, and simulate its intensity and polarity.

|
💐 Baseline |